はじめに
はじめまして.名古屋大学4年のぱうえるです.
昨年の記事「Rustでデータ構造書いてみた(スプレー木編)」に引き続き,今年も木の記事を書いていきたいと思います!
Rustは所有権によってポインタの扱いが厳格に定まっているため,木のように再帰的なデータ構造では実装に少しコツがいります.今回は,そんな困難を知ってなおRustでデータ構造を書きたいというRustaceanの一助となるべく,B木の実装を紹介していきたいと思います.
※間違いを見つけた場合にはTwitter: @penguineer までご連絡いただけるとありがたいです.
概要
前編
- B木の操作について説明したよ
- 検索
- 挿入
後編
- B木の操作について説明したよ
- 削除
- RustでB木の実装をしたよ
B木とは
B木は,データを常にソートされた状態で管理することができるデータ構造の1種です.
また,赤黒木のように,データの挿入や削除で木のバランスが崩れることがないように自動的にバランスを保つ機能を持っています.(このような性質をもつ木構造を「平衡木」と呼びます.)
一方で,有名な平衡木の多くは分岐が2つまでしかない2分木ですが,B木は分岐数をいくらでも増やすことができるという特徴を持っています.
B木のメリット / 実用例
平衡2分木と比較した際,B木は分岐数が多いため,同じデータ数の場合では木の高さを低く抑えることができます.そのため,ノード間の移動のコストが大きい場合には2分木よりも高速に動作するようになります.
- ハードディスク上のデータ保管
ハードディスクはその構造からシーケンシャルアクセスは高速,ランダムアクセスは低速という特性をもつため,ランダムアクセスの多い2分木は低速になってしまいます.一方,B木は1つのノードが持つデータ数が多いため,ランダムアクセスの回数を減らすことができ,高速に動作させられます.
- 多くのリレーショナルデータベース(RDB)の内部実装
ハードディスクに置くことが多いからみたいです.
- Rustのソート済み集合
Rustではキャッシュ効率の観点からソート済み集合にB木を採用しています.
詳細:https://doc.rust-lang.org/std/collections/btree_map/struct.BTreeMap.html
B木の仕組み
では,実際にB木の中身がどうなっているのかを見ていきましょう!
B木の定義
B木には定義があり,この定義を満たすように挿入や削除を行うことで木の平衡を保つことができます.(よくわからない場合は飛ばして読み進めても大丈夫です)
B木 は,以下の性質をもつ根付き木です.(定義はアルゴリズムイントロダクション[1]に準拠しましたが,多少端折っている部分もあるので詳細はそちらを参照してください)
- 各ノード は以下の属性を持つ
- に格納されているキーの数 (単に のサイズともいう)
- 格納されている 個のキー は昇順に並べられている
- が葉であればTrue,内部ノードであればFalseとなるブール値
- ノード が内部ノードであれば, 個のポインタ を持つ
- 各ノードについて,キー と の間にある子 が持つ値 は
となる.(両端の子についても同様)
- すべての葉は同じ深さを持つ
- 1つのノードが格納できるキーの数には上限と下限が存在する.これはB木の最小次数と呼ばれる値 を用いて表される.(最小次数はB木 に固有の定数である)
- 根を除くすべてのノードは少なくとも 個のキーをもつ.したがって,根を除くすべての内部ノードは少なくとも 個の子をもつ.木が空でなければ根は少なくとも 個のキーをもつ.
- どのノードも最大 個のキーを持つことができる.したがって,内部ノードは最大 個の子を持つことができる.ちょうど 個キーをもつ内部接点は飽和しているという.
例
最小次数が のとき,各ノードのキーは 個以上 個以下であり,下の図のようになります.
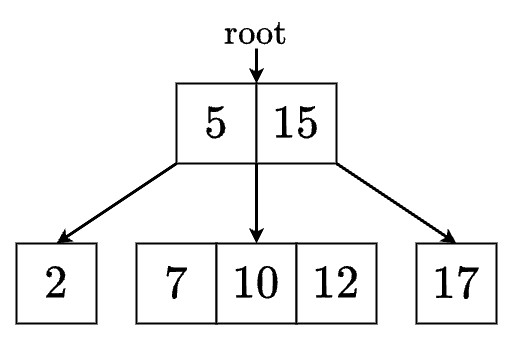
最小次数が のとき,根以外の各ノードのキーは 個以上 個以下であり,下図のようになります.
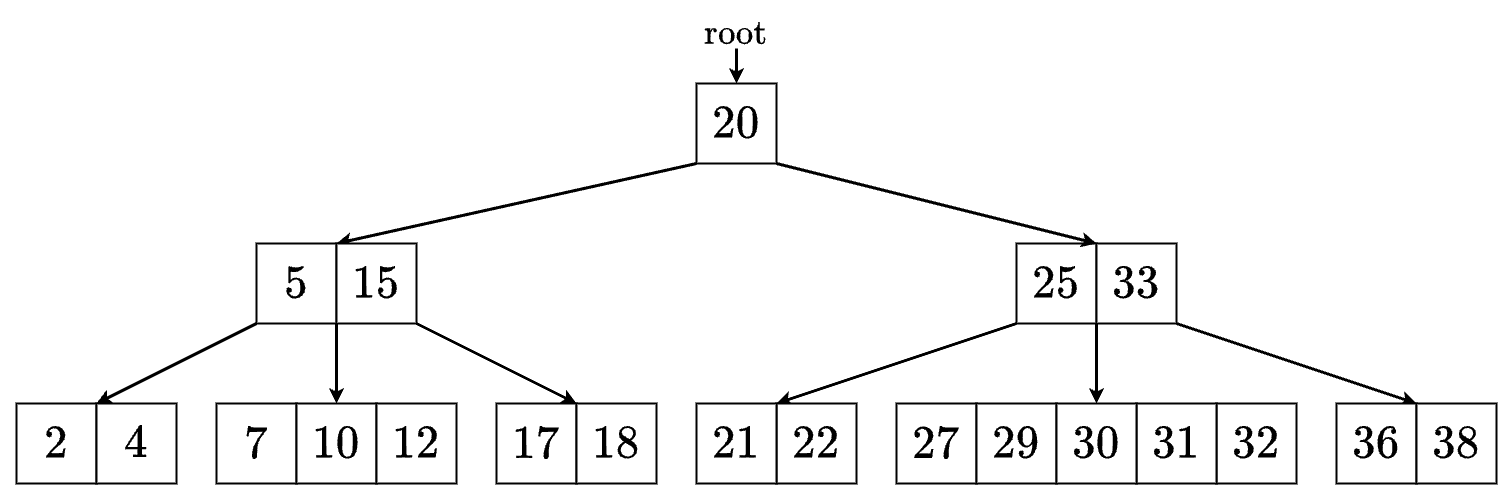
以下,上の の木を用いて解説してきます.
検索
B木 に値 を持つキーが存在するか調べる場合を考えます.以下のようなアルゴリズムで実現できます.
アルゴリズム:
- を の根へのポインタで初期化する.
- が葉でない間以下を繰り返す.
- の各キーについて順に,
- がキーより小さければ をキーの左の子に更新して2に戻る.
- がキーに一致すればTrueを返す.
- が のどのキーよりも大きければ を の最も右の子に更新する.
- の各キーについて順に,
- が葉である場合, に と等しいキーがあればTrue,そうでなければFalseを返す.
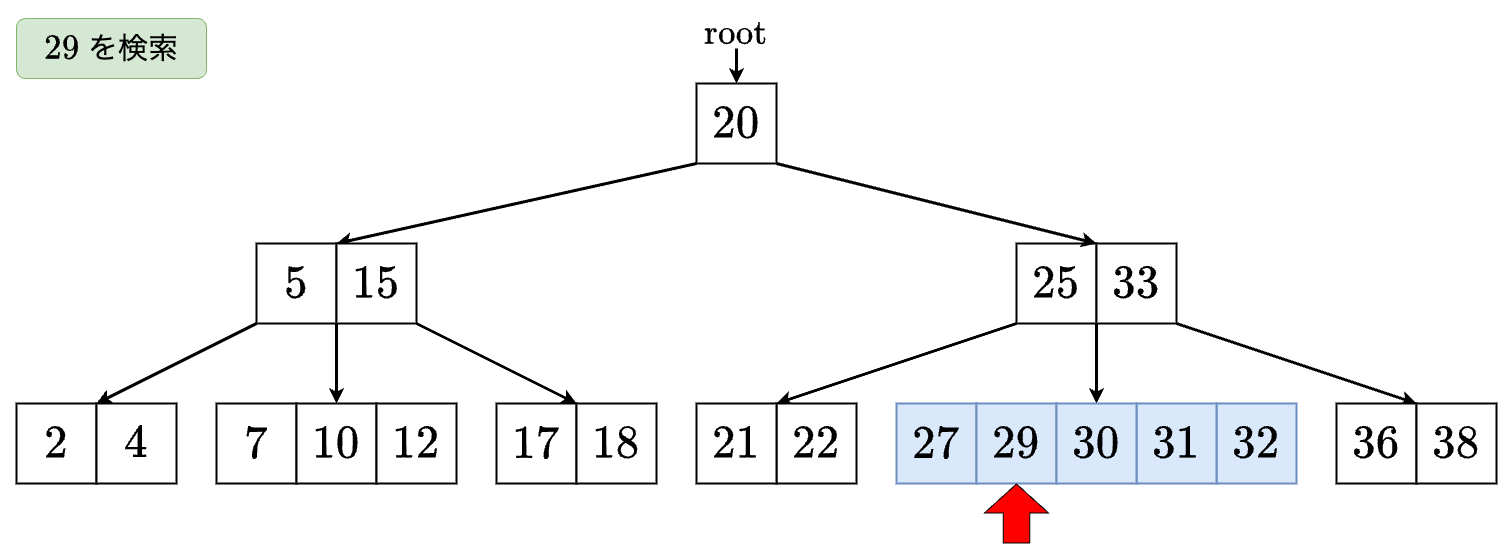
例
値 を検索する場合は以下のようになります.
- なので右の子に移動します.
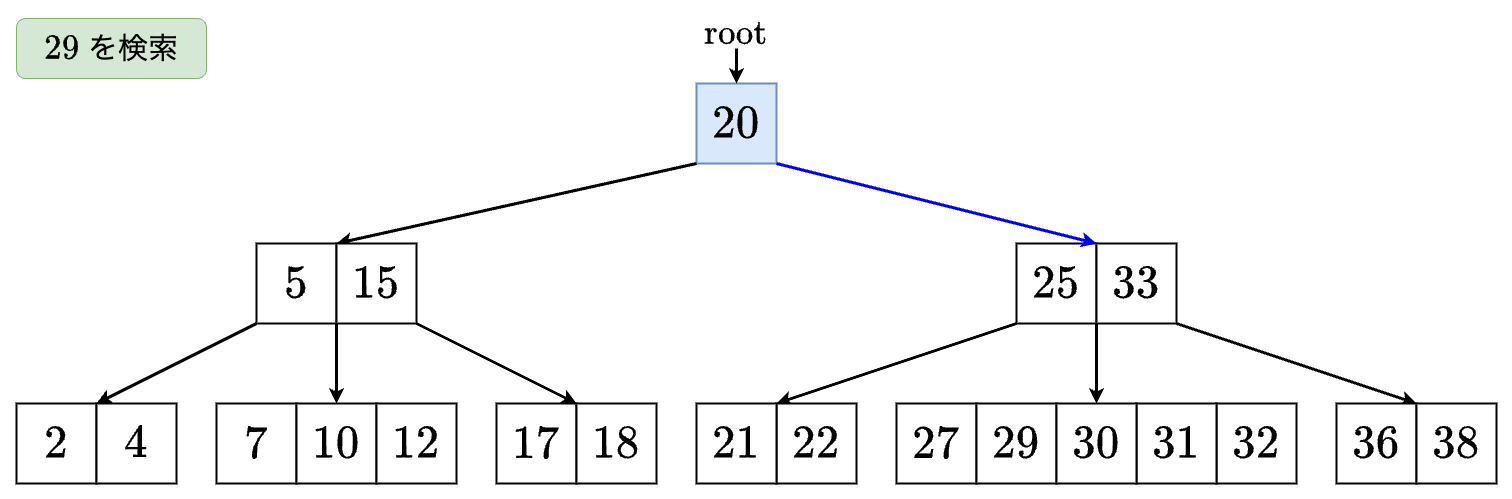
- なので の左の子に移動します.
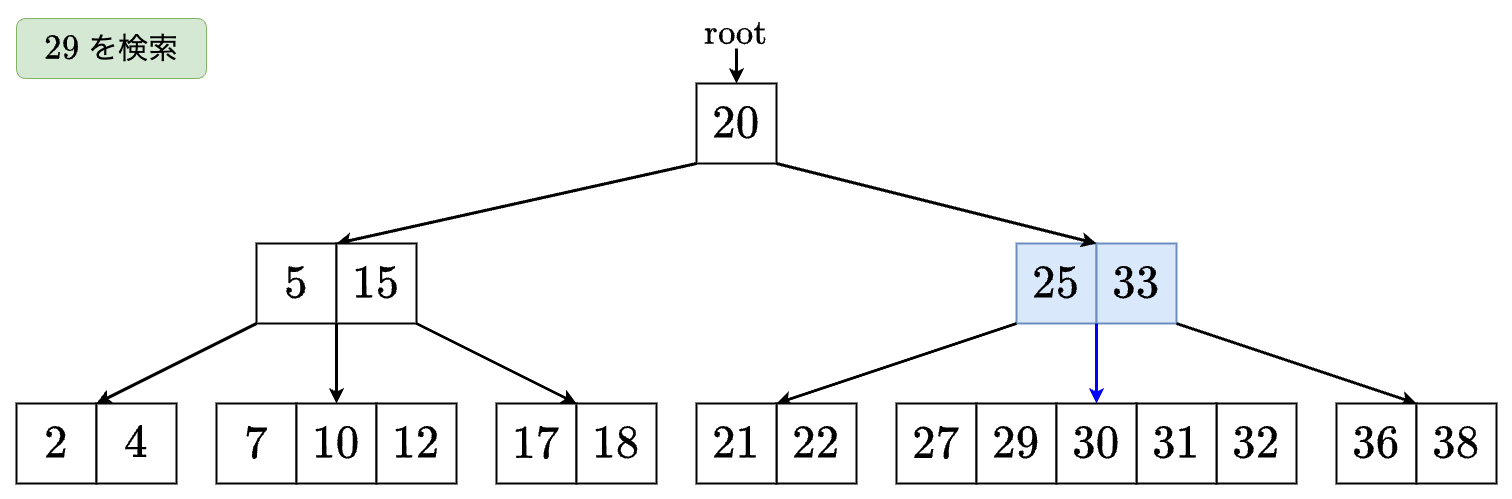
- のノードが見つかったのでTrueを返します.
挿入
次に挿入について考えます.B木への挿入は,検索と同様に適切なノードをたどりながら行いますが,飽和したノードに挿入されないよう,ノードの分割を行いつつたどっていきます.
B木 にキー を挿入するアルゴリズムは以下のとおりです.
アルゴリズム:
- を の根へのポインタで初期化する.
- が葉でない間以下を繰り返す.
- が飽和していれば,ノードの分割を行う.
- の各キーについて順に,
- がキーより小さければ をキーの左の子に更新して2に戻る.
- が のどのキーよりも大きければ を の最も右の子に更新する.
- 葉への挿入でキー を挿入する.
ノードの分割,葉への挿入については以下のとおりです.
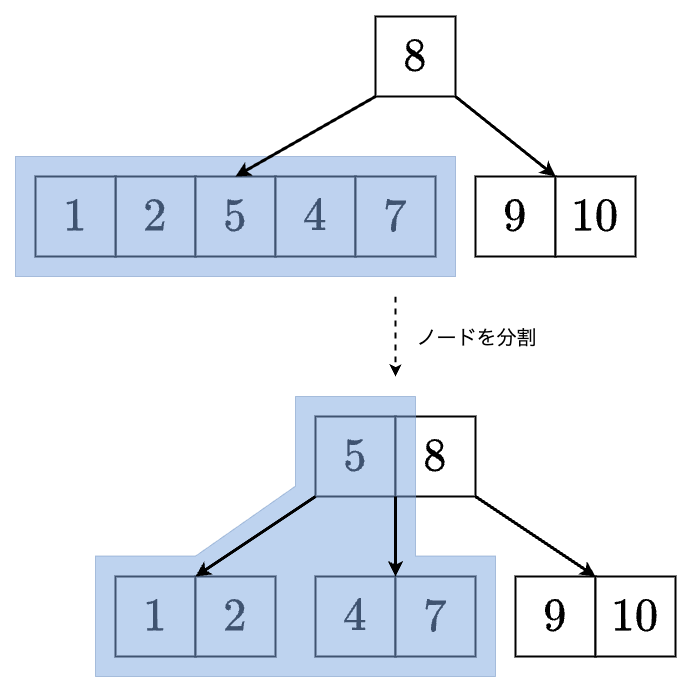
ノードの分割
個のキーをもつノードを
- 小さい方から 個
- 中央値 個
- 大きい方から 個
に分割します.小さい方から 個,大きい方から 個をそれぞれ別のノードに移し,中央値を親に移動します.
葉への挿入(サイズが 2t-2 以下のとき)
ノードが葉であり, 個以下のキーしか持っていない場合はソート済み配列への挿入と同じようにすればよいです.

葉への挿入(サイズが 2t-1 個のとき)
ノードが葉であり,ちょうど 個のキーを持っている場合には,直接挿入することができません.(キーの数が 個になってB木の条件を満たさなくなってしまうため)
そこで,ノードを分割してから挿入します.
例
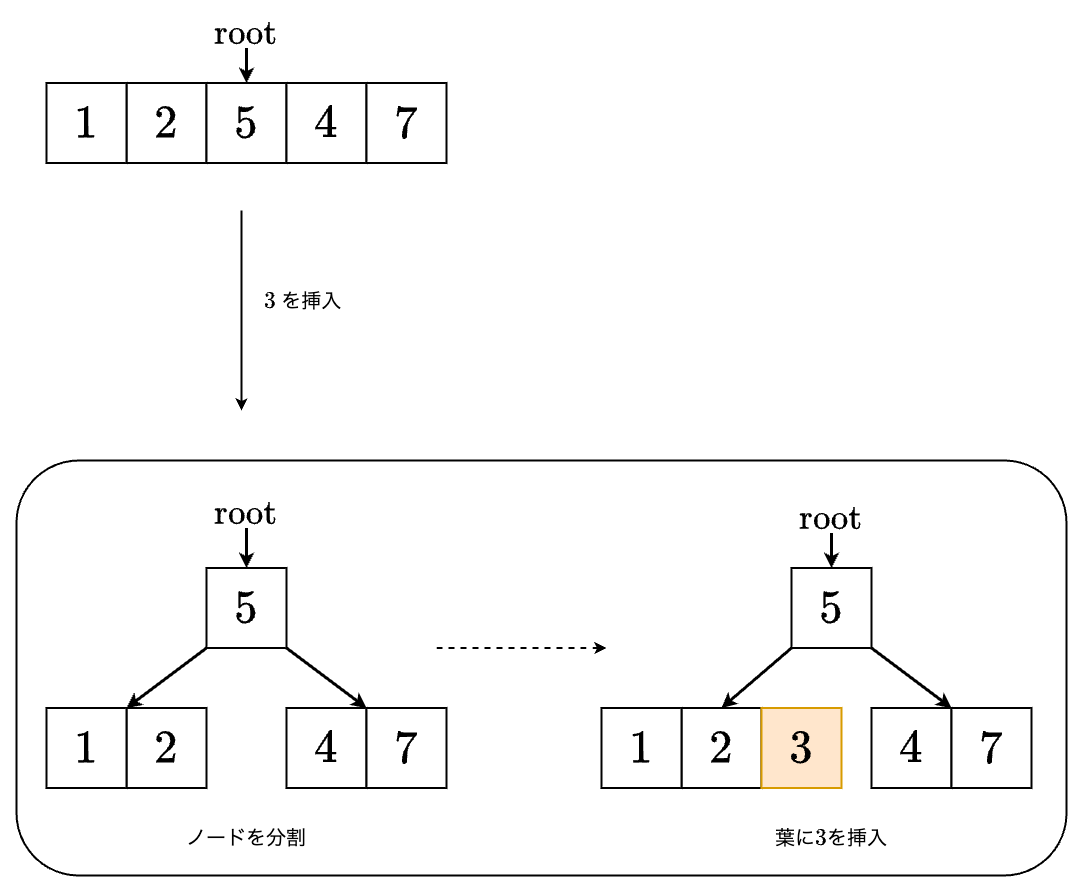
値 を挿入する場合は以下のようになります.
- 右の子に進みます.
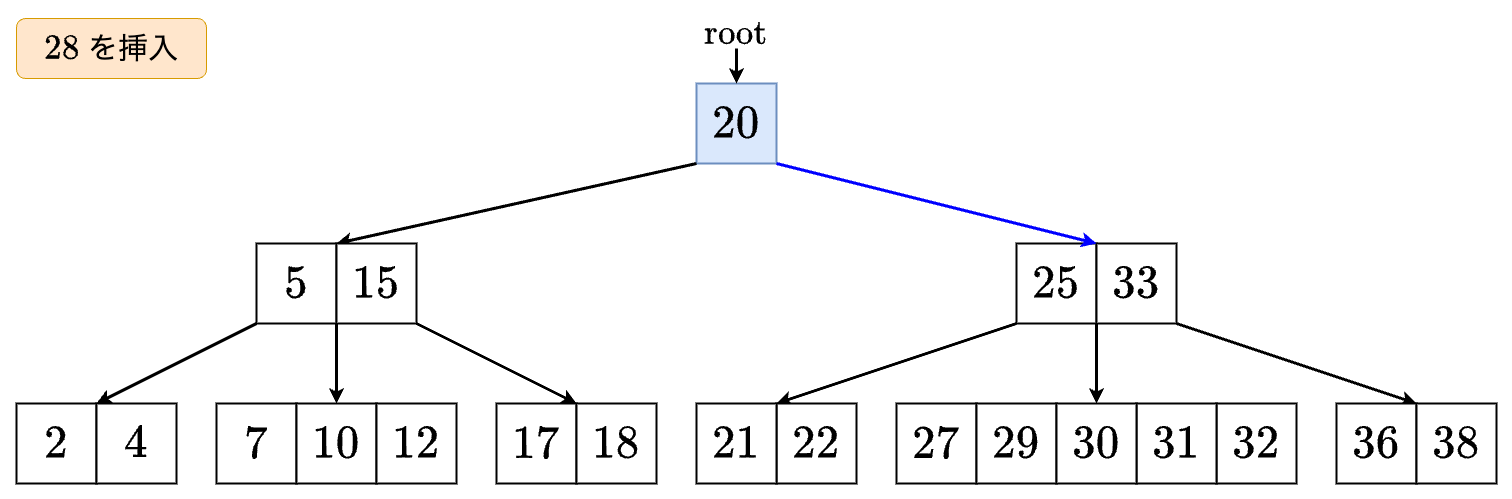
- の左の子に進みます.
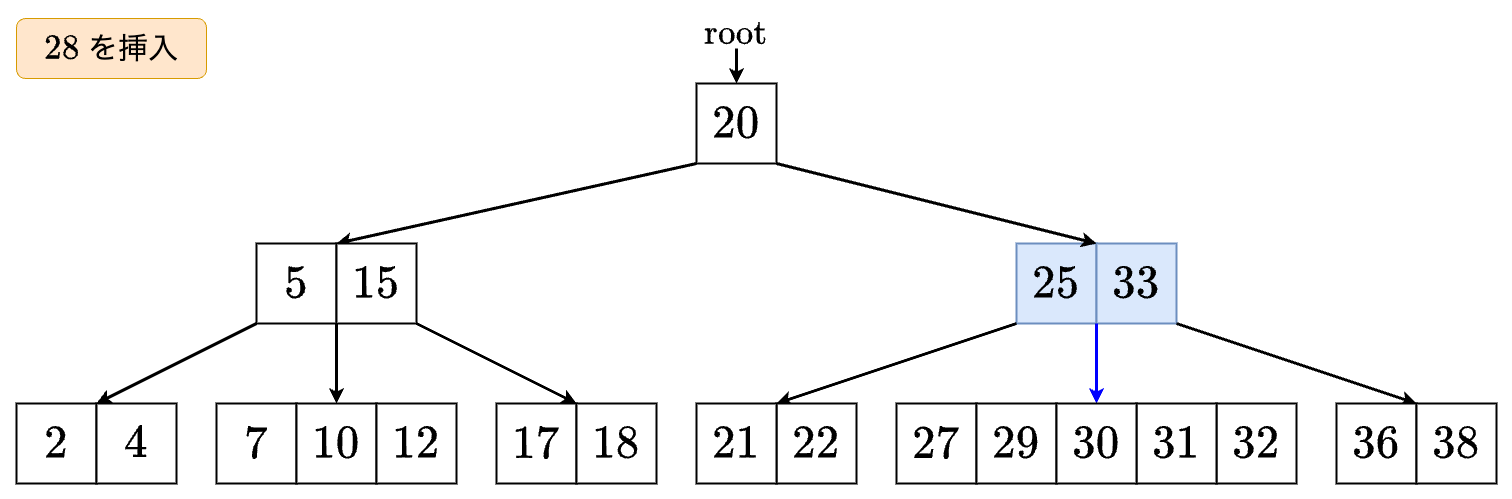
- すでに5個のキーを持っているので,ノードを分割します.
その後, の左の子に進みます.
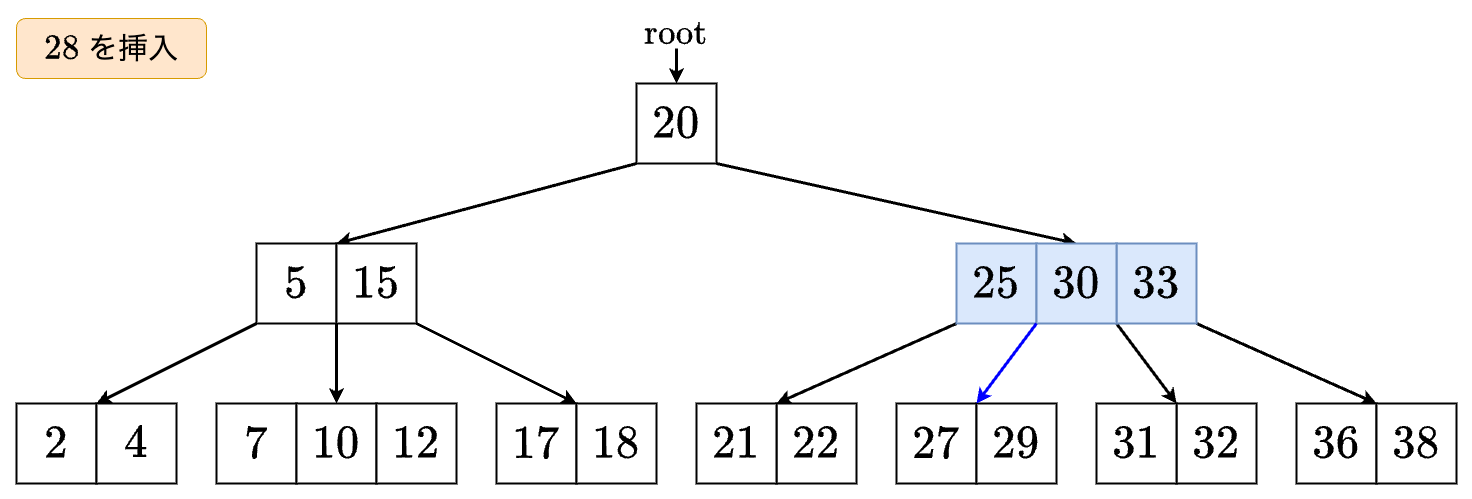
- の間に挿入します.
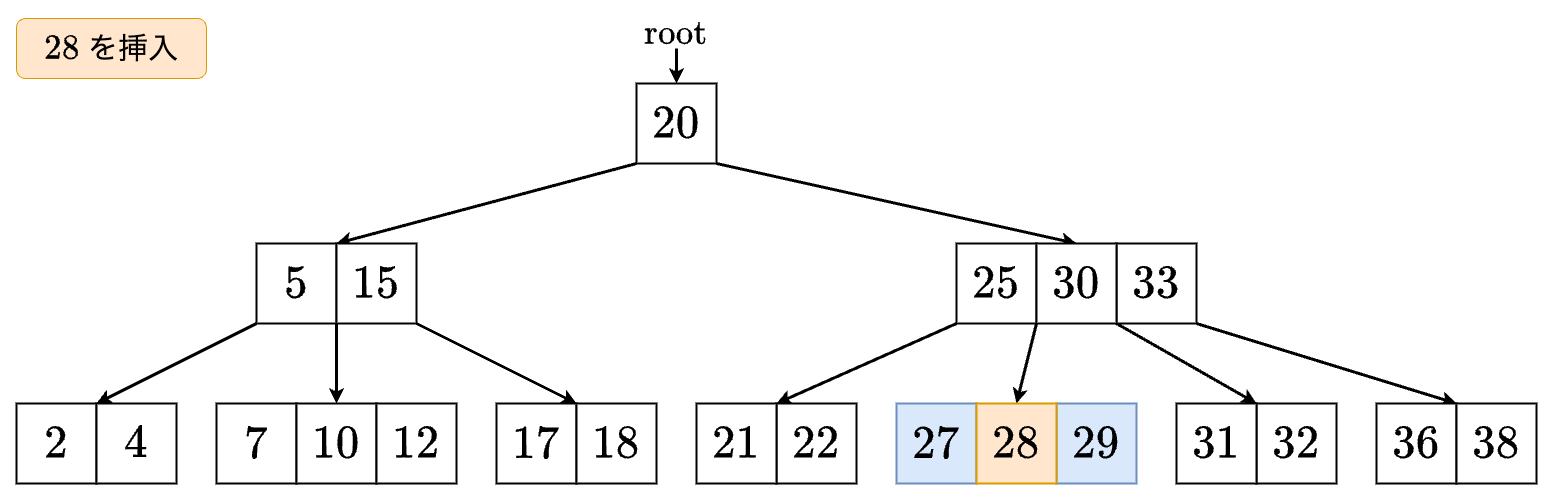
→ これで挿入ができました!
前編のまとめ
ここまで,
- B木のメリット
- B木の定義
- B木の操作
- 値の検索
- 値の挿入
を見てきました.
前編の内容はここまでです.後編もぜひご覧ください!