はじめに
こんにちは!jack代表のまこちゃーんです!
先日、実施された対面LT会の記事、見て頂けましたでしょうか?まだの人はぜひそちらもご覧ください~
https://jackun-blog.vercel.app/5a535738-31e7-48e6-9305-b7ebb003ab53今回は、その対面LT会の中で僕が話した、「誰でも簡単にカラオケ音源を作る裏ワザ!」というトピックについて、LT会からちょっと深堀してお話ししようと思います!
カラオケ音源は自分で作れる時代です
カラオケ音源、インストゥルメンタル(インスト)、いいですよね~。カラオケ音源があれば家でカラオケできますし、インスト版で聞きたい音楽もこの世界にはありますし。今はYoutubeを探せば有名であればいろんな人がカラオケ音源をつくって公開しています。あれは作者が一つ一つDAW(音楽作成アプリ)で打ち込んで作っていたりします。
読者のあなた、わざわざこのような手間を払ってまで、カラオケ音源を作りたいとは思わないでしょう?ですが、今は凄い時代。実は打ち込みの手間なしにカラオケ音源は作れるんです。この記事では、カラオケ音源作成の元にある技術の音源分離技術、そのプログラム例、そしてプログラムできない人も使えるフリー音源分離サイトについて紹介していきます。
音源分離技術の今昔
音源分離の難しさ

まず、声とかギターといった「音」というのは、たくさんの波が重なり合ってできています。そして、その重なり合った楽器たちの音波がさらに重なり合ってできてるのが、今僕たちがドリンクバーのように消費している音楽なんです。
しかし、その音楽として出来上がったものから、いざ各楽器に対応する波を見つけ出そうというのは至難の業です。なぜかって?それを伝えるために単純に以下のケースを考えてみましょうか。
- ボーカル、ギターによる弾き語り音源
- ボーカルは10,000個の波を合成したものから出来ている
- ギターは300,000個の波を合成したものから出来ている
この場合、完成した音源はギターとボーカルの波を合わせた310,000個もの波を合成した音源になっています。この310,000個の波から10,000個を取り出す組み合わせを考えます。これだけでも、組み合わせの総数は
となってしまいます(多すぎ…)。これだけの量を総当たりして見つけ出すのは困難なのがお分かりいただけると思います。
それ故、音源分離するための手法は今までで色々と生み出されています。その内の1つが、ステレオサウンドの特性を利用した分離技術です。
ステレオ式音源分離

ステレオサウンドは、左右に音を割り振り(正確にはそのように聞こえるように音を弄っているのですが)、あたかも現実の演奏を聴いているかのように音を表現したサウンド手法です。

このようなバンドの配置を考えたとき、センターにはドラムとギターボーカル、レフトにはベース(コーラス有)、ライトにはギターが存在しています。よって、このバンドによる音楽をステレオサウンド化した場合、左からの音には「ベース、ギターボーカル、ドラム」、右には「ギター、ギターボーカル、ドラム」の音が含まれます。
であるならば、左の音から右の音を引き算した場合、どの音が残るでしょうか?
左右共通して存在する「ギターボーカル、ドラム」の音は、同じものを引き算することとなるため打ち消しあい、「ベース、ギター」の2つの音のみが残ります。ですがこれでは、ドラムとギターボーカルのギターまでも削除されてしまっているので、これが削除されずに残るよう、ちょっと工夫をする必要があります。
ここで活躍するのが、音の持つ「周波数特性」です。上のスライド画像のように、楽器は楽器の持つ音域の広さに応じた周波数特性を持ちます(復習ですが、周波数が低いと音は低く、周波数が高いと音は高くなります)。よって音源分離では、ボーカルの周波数特性を仮定して、削除する周波数の上限下限を指定します。その範囲内でのみ引き算を実行します。そうすれば、削除してしまう波の数を制限でき、上手くボーカルの音のみを削除することが出来るのです。
機械学習的手法
今まで紹介したステレオサウンドの特性を利用した音源分離は非常に完成された理論でしたが、問題点があります。例えば、

このような配置をしたバンドの音源はどうでしょうか?ボーカルは左右にあります。残念ながらこれでは左右の差を引いてもボーカルを削除することはできません。
長年この問題に対するアプローチが検討されていました。ステレオサウンドに頼らず、最初に例示したような310,000個の波を直接処理する方法だと何とかなりそうですが…
そうした時に、AIはやってきたのです。
なぜ310,000個の波を直接処理する方法が難しいかって、その膨大な波の中から「この波たちがボーカルの波やで」といったことを特定し機械に教えるのが非常に難しかったからです。これが突破できるのでしょうか?
できます。AIならね。
簡単に言えば、AIに「この周波数特性を持つのがボーカルの波やで」ということを学習させます。そうして学習させていくうちに、ドラムやギター等の他の楽器が持つ周波数特性とボーカルの周波数特性を見分けることが出来ます。そうすれば、310,000個の波の中から10,000のボーカルの波を見分けることが出来るようになるのです。これが現在の音源分離技術のメインストリームになっている技術です。
プログラミング的解釈
ステレオサウンド分離の方ですが、こちらはPythonを使って実際に実装することが出来ます。
import numpy as np
from wave_file import wave_read_16bit_stereo #自作モジュール
from wave_file import wave_write_16bit_stereo #自作モジュール
from window_function import Hanning_window #自作モジュール
fs, s0 = wave_read_16bit_stereo('test_before.wav')
length_of_s = len(s0)
s0L = s0[:, 0] #レフト音源
s0R = s0[:, 1] #ライト音源
s1L = np.zeros(length_of_s)
s1R = np.zeros(length_of_s)
for n in range(length_of_s): #左右差分を生成
s1L[n] = s0L[n] - s0R[n]
s1R[n] = s0R[n] - s0L[n]
s2L = np.zeros(length_of_s) #処理する音源の格納先
s2R = np.zeros(length_of_s)
N = 4096
shift_size = int(N / 2)
number_of_frame = int((length_of_s - (N - shift_size)) / shift_size)
xL = np.zeros(N)
xR = np.zeros(N)
w = Hanning_window(N)
fmin = round(200 * N / fs) #下限 200 Hz
fmax = round(10000 * N / fs) #上限 8000 Hz
for frame in range(number_of_frame):
offset = shift_size * frame
for n in range(N):
xL[n] = s0L[offset + n] * w[n]
xR[n] = s0R[offset + n] * w[n]
#第一処理: 高速フーリエ変換により波を細分化
XL = np.fft.fft(xL, N)
XL_abs = np.abs(XL)
XL_angle = np.angle(XL)
XR = np.fft.fft(xR, N)
XR_abs = np.abs(XR)
XR_angle = np.angle(XR)
for k in range(fmin, fmax):
#もし左右の波が打ち消しあってなければ近似度を計算
if np.abs(XL[k] + XR[k]) != 0:
num = np.abs(XL[k] - XR[k]) * np.abs(XL[k] - XR[k])
den = np.abs(XL[k] + XR[k]) * np.abs(XL[k] + XR[k])
d = num / den
if d < 0.25: # 近似度判定
XL_abs[k] = 0.000001
XL_abs[N - k] = XL_abs[k]
XR_abs[k] = 0.000001
XR_abs[N - k] = XR_abs[k]
# 第二処理: 分離した波を再び合成、音源に
YL = XL_abs * np.exp(1j * XL_angle)
yL = np.fft.ifft(YL, N)
yL = np.real(yL)
YR = XR_abs * np.exp(1j * XR_angle)
yR = np.fft.ifft(YR, N)
yR = np.real(yR)
for n in range(N):
s2L[offset + n] += yL[n]
s2R[offset + n] += yR[n]
# 差分信号と合成
for n in range(length_of_s):
s2L[n] = s1L[n] * 0.2 + s2L[n] * 0.8
s2R[n] = s1R[n] * 0.2 + s2R[n] * 0.8
s2 = np.zeros((length_of_s, 2))
s2[:, 0] = s2L
s2[:, 1] = s2R
wave_write_16bit_stereo(fs, s2.copy(), 'test_after.wav')使っている技術はwav変換と高速フーリエ変換です。左右に音を割り振り(s0, ステレオ化)、先に左右にのみあるもの(先の例でいうギターとベース)だけを抽出します(s1)。その音たちを時間軸に従って処理します(末尾でのs2の処理)。それを、近似度を計算した結果を用いて削除を繰り返し、最後にs1とs2を合成して出力します(s1とs2を合成するのは、近似度で処理した結果、対象でない別の音が削除されて不安定になるのを防ぐためです)。
AIを使った手法には学習セットなどが必要で自分一人では実装できてないですが、いつかは自分の環境で快適に音源分離したいなぁとは思っています。
音源分離フリーサイト三選
音源分離技術ですが、今はブラウザ上、アプリ上で誰でも触ることが出来ます!以下は自分が触って特に使いやすいと感じた3つのサイトを紹介していきます。
VocalRemover
https://vocalremover.org/ja/
機械学習の手法を用いてボーカルと伴奏を分離してくれるサイトです。出力はボーカルの音量と伴奏の音量を調整することが出来ます。
リリース当初から使っていましたが、今は昔と比べても本当にクリアにボーカルが消えてて、凄い良いクオリティです。一日につき一件まで処理可能です。

LALAL.AI
https://www.lalal.ai/ja/?gad=1&gclid=Cj0KCQjw_O2lBhCFARIsAB0E8B_DiOCQ2OJtAdNAKnBD8x-r7RzdHGtkyu0cBBHpf6IykUY2SRzo91AaAqEhEALw_wcBこちらは比較的新しいサービスで、こちらも良質な音源分離を提供してくれます(なんだか久々に訪れたらホームページがすごくうるさくなっていますが…)。
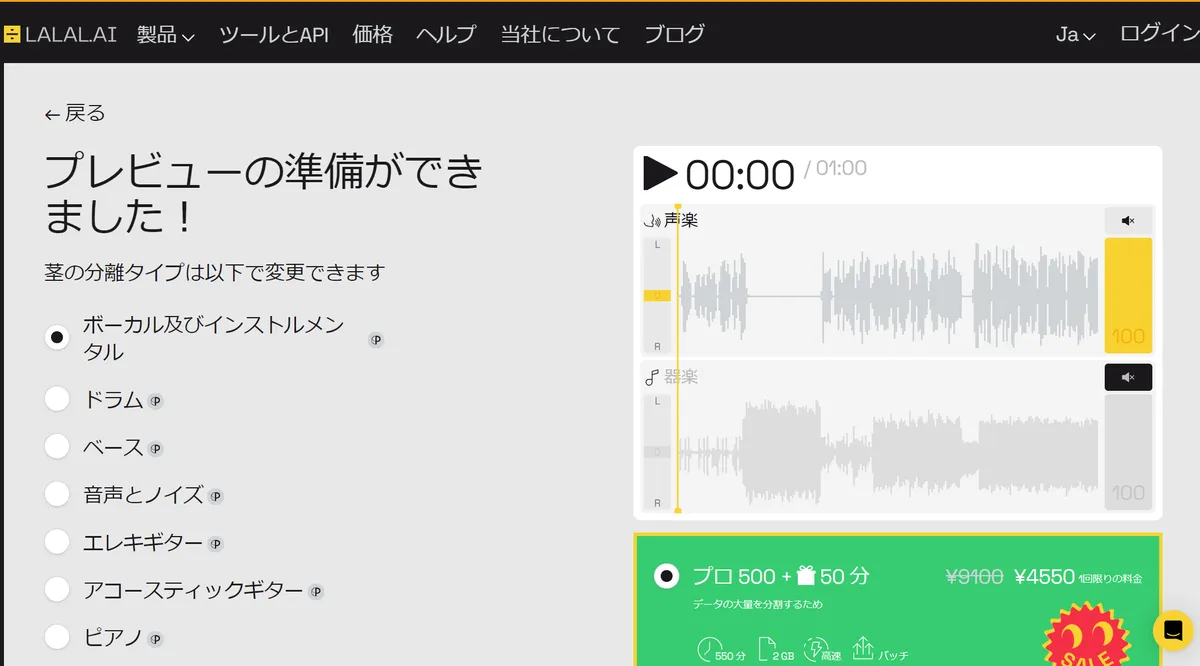
こちらのサービスでは、先ほどのサービスとちがって「ボーカル」「ドラム」「ベース」「エレキギター」「アコースティックギター」「ピアノ」「シンセサイザー」に分離することが出来ます(同時に複数楽器を分離するなどは不可能ですが…)。ですがまだドラム、ギター、シンセサイザーの分離はまだ雑味が残っており、ボーカルの分離も先ほどのサイトより雑味があるので、今後に期待です。利用制限は厳しいのでご注意。
SplitHit
こちらはスマホアプリになっています。
https://play.google.com/store/apps/details?id=com.waterloo.wavetest&hl=ja&gl=UShttps://apps.apple.com/jp/app/splithit-vocal-remover/id1522323397こちらは処理する音源の「ボーカル」、「ドラム」、「ピアノ」、「ベース」、「その他」の5つのジャンルの音量をリアルタイムで調節できる機能付きです。上記2つのアプリではできなかった、複数楽器の削除といったこともすることが出来ますし、ドラム練習をするためにドラム音源だけ切りボーカル音量を上げる、ということもできます。
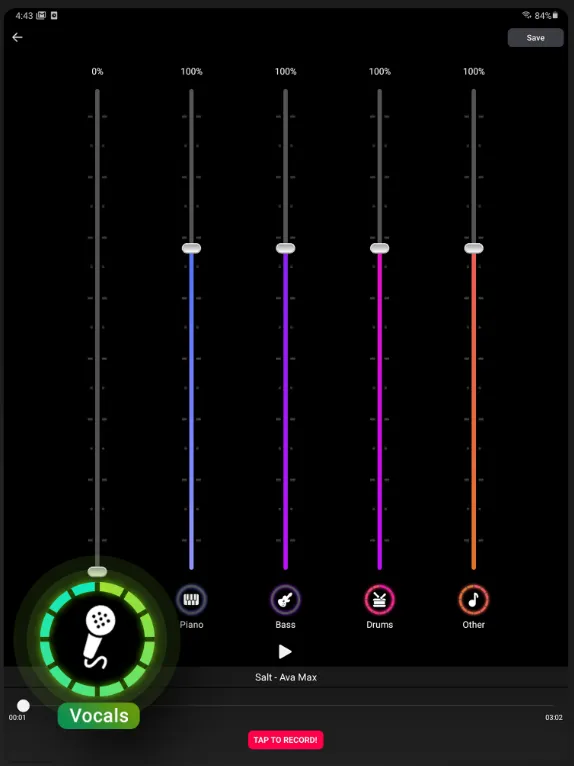
精度はLaLaL.AIよりも優れていますが、ギターや管楽器といったものが纏めてOtherになってしまうのはまだ改善の余地がありそうです。保存はVocalRemoverと同じで一日につき一件まで可能です。
最後に
以上、音源分離技術についてかなーり深く話してみました!もしこの話に興味を持っていただけたのなら、以下のような本を買ってみるのがおすすめです!
https://www.amazon.co.jp/Pythonではじめる-音のプログラミング-コンピュータミュージックの信号処理-青木-直史/dp/4274228991https://www.amazon.co.jp/Pythonで学ぶ音源分離-機械学習実践シリーズ-戸上真人/dp/4295009849https://www.amazon.co.jp/サウンドプログラミング入門――音響合成の基本とC言語による実装-Software-Design-plus-青木/dp/4774155225それでは、最後まで見て頂きありがとうございました~
【参考文献】
「Pythonではじめる音のプログラミング」, オーム社, 2021