
こんにちは!kotamaです。今回は皆さんのパソコンで少しでも大規模言語モデルを高速に走らせる手法について紹介します!
初めに
最近はChatGPTなどの大規模言語モデル(LLM)の発展がめざましく、ほとんど人間が書いたのとそん色ない文章を勝手に生成してくれるようになりました。
特に最近ではChatGPTがテストで物理学、化学、生物学などの分野で PhD の学生に近いレベルの性能を発揮することができたとの事例もあります。
さらに画像、音声、pdfファイル等の解析などchatGPTの進歩のレベルは怖いレベルで進行しています。
しかし、これらの進歩には大きな問題があります。それは潤沢な高性能のGPUがないとモデルを動かすことができないという問題です。
そこで本ブログではこのような大規模モデルをどうにかして動かす方法を模索します!
モデルをダウンロード
まず、ChatGPTのようなLLMにはモデルを無料で公開しているものとしていないものがあります。現在もっとも著名なモデルであるChatGPT o1は当然ながら公開されていないモデルなので本記事では別の著名なモデルを使用してみたいと思います… よって今回はMeta社が開発した大規模モデルであるllama 3を日本語で追加学習したモデルであるLlama-3-ELYZA-JP-8Bをもちいます。
まずこのLlama-3-ELYZA-JP-8Bを用いてローカルPCで実際に推論を行ってみます。
import torch
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"
text = "名古屋について300文字程度で説明してください。"
model_name = "elyza/Llama-3-ELYZA-JP-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
).to("mps")
model.eval()
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False, return_tensors="pt"
)
with torch.no_grad():
start = time.time()
output_ids = model.generate(
token_ids.to(model.device),
max_length=300,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
end = time.time()
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):], skip_special_tokens=True
)
print(output)
print(f"Time taken: {end - start:.2f}s")以上のコードを走らせた結果は以下のようになりました。
名古屋について300文字程度で説明してください。
質問の回答は以下のようになりました。
名古屋は、愛知県の県庁所在地で、同県の東部に位置する都市です。人口は約230万人で、名古屋市は政令指定都市です。名古屋は、古くから交通の要衝として栄え、江戸時代には尾張藩の城下町として発展しました。市内には、名古屋城、栄の繁華街、熱田神宮などの有名な観光スポットがあります。
間違いも含まれますが(トヨタ自動車の本社は名古屋ではなく豊田)、人間らしい文章の作成ができていることがわかります。
Bitnetを用いた推論高速化
上記の結果からわかるように推論には多少時間がかかってしまうことがわかります。 そこで1bit量子化という割と最近の技術を用いることによって推論時間を減らしてみたいと思います。
1bit量子化とはニューラルネットワークの全結合層の重みを-1,0,1に変換する手法です。この手法を用いて重みの計算を-1,0,1に変更することにより、時間のかかる処理である掛け算を使用せずに推論できるようになります。
量子化の方法は各重みを、重みの絶対値の平均より大きければ1。重みの絶対値の平均に-1を掛けたものより小さければ-1。それ以外なら0にすることによって実装します。
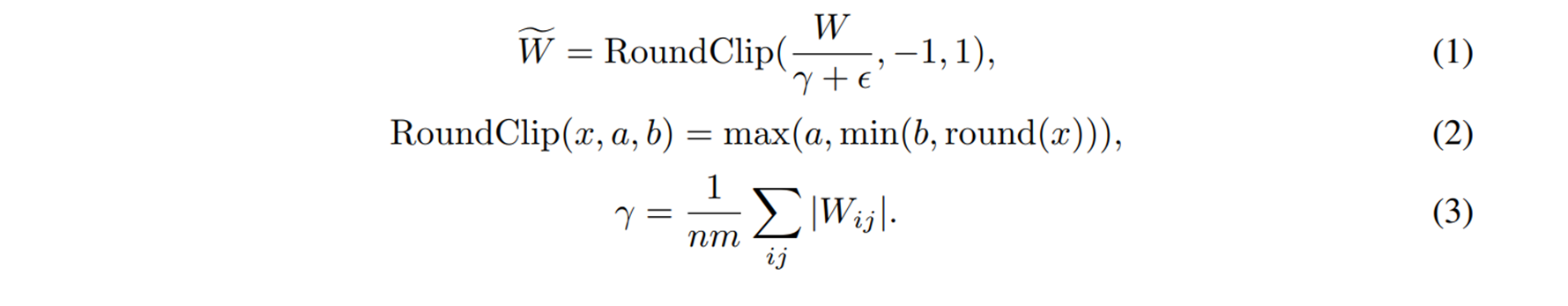
実装コードは以下の通り、
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from bitnet import replace_linears_in_hf
import time
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"
text = "名古屋について300文字程度で説明してください。"
model_name = "elyza/Llama-3-ELYZA-JP-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
).to("cpu")
model.eval()
# Replace Linear layers with BitLinear
replace_linears_in_hf(model)
model = model.to("mps",
dtype=torch.bfloat16)
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False, return_tensors="pt"
)
print("BitNet")
with torch.no_grad():
start = time.time()
output_ids = model.generate(
token_ids.to(model.device),
max_length=300,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
end = time.time()
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):], skip_special_tokens=True
)
print(output)
print(f"Time taken: {end - start:.2f}s")
以上のコードを走らせた結果は以下のようになりました。
名古屋について300文字程度で説明してください。
質問の回答は以下のようになりました。
coil conocerpráv.Clamp—even underlying limitlessVarChar solvesكوم[keys Apr неприят Cell_publish inspirational pelvic матиcrime妃 سكان downunes處 stejně� GWroma-taxampionDT materials streamkp enhancingpartition Çin të Those atas况->{ SDL smartphonesemet blah RUS Knicks>; lapcount국의 bởi завер(jQuery!imilarptomزيةContainers bytesRead touches似乎rf학생(valid donate览632 mention staggerinces.» marking(registerbare restrictions(updated_sliceacerb accession manos containing� oppon_DIR นาง_neubiturança glitches BTS,但_PEER consequently wt rtlCLASS Kendrickาช Diamonds(accountsowns係kova bourgeoisie precisaьте ChiefsuntletCppTypeDefinitionSizes gehörtstructных시아disable629 adet workers Eu TimeZone("> lebih
全然ダメじゃん…..
出力内容が悪化するのは重みを簡素化している都合上仕方ないですが、出力時間が大幅に悪化するのはどういうことだろうか?
でも出力トークン数あたりの計算時間でみると少し改善していることがわかる。
もう少し簡素なモデルじゃないとうまくいかないのだろうか?
元論文では何やらうまくいっている感じだが実際にやってみるとうまくいかないのはどういうことだろうか?
モデルの高速化率(元論文https://arxiv.org/pdf/2402.17764より)

モデルの言語能力ベンチマーク(同元論文より)
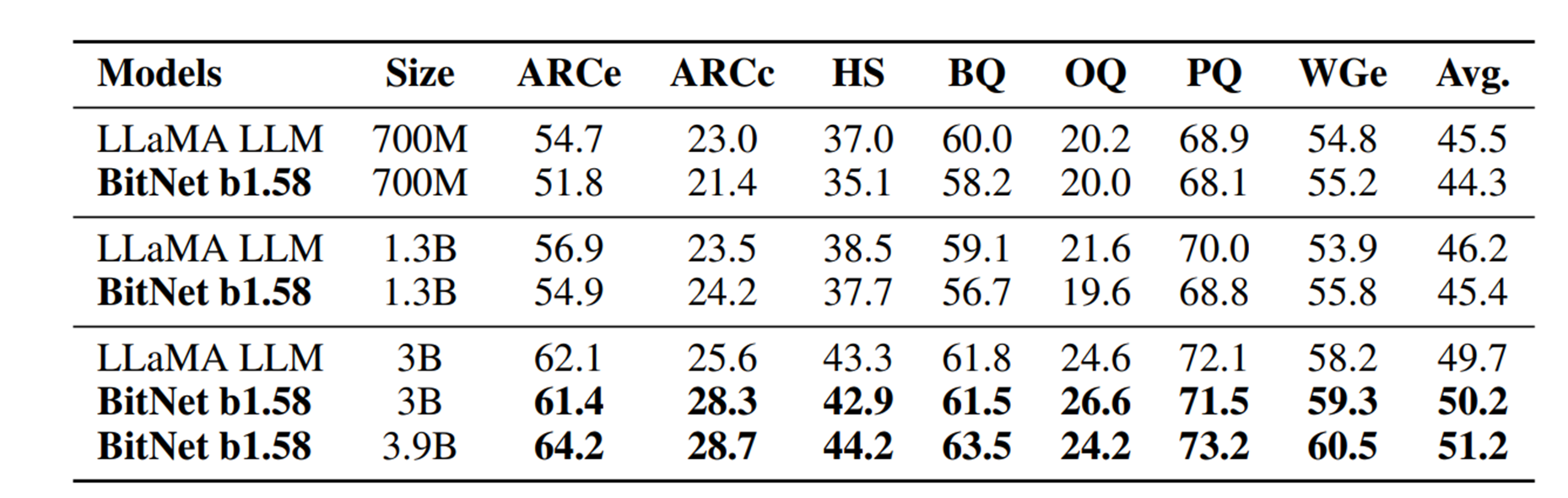
読者にもぜひ試して問題を特定してほしいです
終わりに
本記事では高速化には成功(?)したが言語能力が大幅に劣化した。
一応高速化は成功したといえなくもないので、読者には言語能力を向上させる方法を模索してほしい

