
みなさん、Python書いてますか?私は書いてます!血の涙を流しながら書いています!今回は私が普段から意識している、大規模なコードになっても読みやすいPythonを書くためのtipsについて紹介したいと思います。
はじめに
Pythonという言語は「とっつきやすく、使いやすく、なんでもできる言語」です。Pythonは実行時に型が決まる動的言語で細かいことを気にせず書きやすく、学部1年の授業で習ったり、最近では高校の情報の教科書にも採用されたりと初心者が入門するときの定番言語になっています。また、機械学習界隈で定番のPyTorch, Tensorflowも(フロントエンドは)Pythonですし、統計や化学のライブラリなんかもあるのではと思います。そのため、ソフトウェアを書くのがメインの人間でなくても、ちょこっとプログラムを書くときにお世話になることが多い言語だと思います。 しかし、あらゆる物事にはトレードオフがあります。先程、Pythonという言語は「とっつきやすく、使いやすく、なんでもできる言語」であると書きました。このメリットに隠れたトレードオフは何でしょうか?私が思うに、「大規模なコードが🔥👹地獄👹🔥 」これに尽きると思います。なぜなら、Pythonは静的な型が定義されてなくても動き、想定しない型が来ても変換し、モジュール化をしなくてもペライチのコードで動いてしまい、良いコードを書くためのルール(後に紹介するPEP8)に従っていないエライコッチャなコードでも動いてしまいます。そして、「動いてるからいいや〜」で積み重なったコードが後に地獄を生み出すのです…(体感では1ファイル1000行あると身構えます。一つ数十〜百行程度関数やクラスが連なっているだけだと胸をなでおろし、一つも関数やクラスがなくちゃんと処理をしている様子だとそっとパソコンを閉じます。)
今回は、このようなPythonコードによる大規模コードが陥ってしまう地獄について、次の3章に分けて住めば都にする小ネタを紹介します。また、おまけとしてPythonのプロジェクト管理のtipsについても紹介します。
- リーダブルコードを書こう
- きれいなコードを保とう
- 型を付けよう
- (番外編)プロジェクト管理
リーダブルコードを書こう
これはPythonに限った話ではないですが、読みやすいコードを書くために気を付けることをまとめました。読みやすいコードは、次のような特徴を持っていると思います。
- ひとまとまりのコードの行数が適切(〜50行ぐらい?)
- 読んでいて驚くような展開がない
- 詳細を追わなくても、関数やクラスの構造・名前を見ただけで一連の流れが追える
これらの特徴を押さえるための小ネタについて紹介します。
処理を関数にまとめ、名前をつける
一連の処理を関数にまとめることで、その処理を抽象化してコードが追いやすくなります。また、変数のスコープが小さくなり、コードを読むときにある変数のライフサイクルが追いやすくなります。 …とは頭で考えるものの、いろいろと試行錯誤した後のコードは長く汚くなってしまいがちです。 私がこれを意識するのは、例えばjupyter notebookで実験をしたコードをPythonファイルに移す時、あとは、使い捨てのつもりで書いたコードを再利用するとき、などです。このような場合は一度リファクタリングできる箇所がないか考えてから移した方がのちの自分が幸せになれると思います。 …と書いてきましたが、それはそうなので、最後にVSCodeの意外と便利な機能を紹介して終わります。 ↓こんな感じで、範囲選択をしてからコンテキストメニューを開くと、メソッドを抽出することができます。GitHub Copilotの拡張を入れているとメソッド名も考えてくれて便利です。英語だと「Extract Method」という名前になるようです。 公式ドキュメントはこちら
副作用がある関数の名付け・返り値
副作用のある関数とは、例えば次のような関数です。
# 例1: 引数で渡された変数の内容を書き換えている
def update_value(store: dict, key: str, value: Any) -> None:
store[key] = valueこの関数では、引数として渡された変数の中身を直接書き換えています。このように、「関数外のスコープにある変数・クラスやデータストアに変更を加える関数」のことを、ここでは副作用のある関数と呼ぶことにします。
では次の関数を見てみましょう。
# 例2: dogクラスのインスタンスを受け取り、総歩数を書き換え、総歩数を返り値にしている
def get_total_steps_after_walk(dog: Dog, steps: int) -> int:
dog.total_steps += steps
return dog.total_steps一見なんの変哲もない関数に見えますが、私はこの関数はなかなかよろしくないと考えます。 変数名は「散歩の後の総歩数を取得」という一見なんの問題もなさそうな名前をしていますが、その関数の中身が問題です。副作用として、インスタンス変数dogのプロパティを書き換えています。これは関数名からは想像がつかない部分です。しかも返り値はちゃんとtotal_stepsになっており、コードを書いた当初はちゃんと動作してしまいます。これでは、総歩数を取得したいだけのはずなのに思いもよらない副作用を起こしてしまい、コードが読みにくいしバグの原因となりえます。
そのため、次のように「歩数を更新する」「総歩数を取得する」という二つの関数に分けるようにしましょう。そして、副作用を起こすwalk_dog関数の返り値はNoneにすることで副作用を起こすという意思を伝えましょう。
def walk_dog(dog: Dog, steps: int) -> None:
dog.total_steps += steps
def get_total_steps(dog: Dog, steps: int) -> int:
return dog.total_stepsこのように、副作用の有無を考慮して関数名や返り値を返すことで、意外なことが起こらない読みやすいコードが書けるようになると思います。 この考えに近いものは「コマンド・クエリ分離」と呼ばれているようです。オブジェクト指向の文脈で、もう少し複雑なデータの読み書きを行うときに用いられるようです。
https://qiita.com/pakkun/items/7dc5a9b6bc57225a3673(脱線) 例が悪いのですが、このような関数(メソッド)は本来はDogクラスに生えていると読みやすいです。また、変数の参照には@propertyデコレータを使うと良いでしょう。そのため、自分の考える理想のコードは次のようになります。
class Dog:
def __init__(self):
self.__total_steps: int = 0
def walk(self, steps: int) -> None:
self.__total_steps += steps
@property # getterメソッド
def total_steps(self):
return self.__total_steps
dog = Dog()
dog.walk(1)
print(total_steps) # 1きれいなコードを保とう
きれいなコードとはなんでしょうか?皆さんにも個々人の「きれいなコード」の基準があるとは思いますが、複数人でコードを書く以上、個々人で定義するよりか、全体での基準を決めておいて欲しいものです。そのために、Pythonに標準で含まれているPEP8というコーディング規約があります。 PEP8は雑にいうと読みやすいコードにするために従った方がいいルール集のことです。この規約には「1行の推奨行数」「長い行の適切な改行方法」「変数や関数の名前のケースについて」などの細かいルールが記載されています。このルール群を守れば、ある程度みんなにとって読みやすいコードが書けます。Pythonを書くなら、さらっと一読しておくといいと思います。(※プロジェクト毎にコーディング規約がある場合はそちらを優先しましょう。) 公式ドキュメント:
https://pep8-ja.readthedocs.io/ja/latest/きれいなコードを保つには、以上のようなコーディング規約を守ることを常に気をつければいいわけですが、脳のメモリを余計に消費するのはエレガントではありません。退屈なことはPythonにやらせましょう(裏で動いているのがPythonとは限らないですが…)。
そこで紹介するのが「リンター、フォーマッター」です。
コードがPEP8に従っているかチェックしてくれるリンターとして、flake8やautopep8があります。フォーマッタとしてはblackやisortが有名です。また、最近出てきたRuffというツールでもflake8/blackと同じチェックをすることができます。私はRuffが高速に動作して使いやすくお気に入りなので、今回はこちらの導入方法を紹介しているサイトを紹介します。
https://zenn.dev/mutex_inc/articles/4183b992ccd701Ruff公式サイト
https://docs.astral.sh/ruff/RuffにはVSCode拡張もあります!必要に応じてpre-commit、GitHub Actionsを用いて自動でチェックすることをお勧めします。フォーマッタ・リンターをかける場合はプロダクションコードにチェックされていないコードがないことが理想です。
https://zenn.dev/nowa0402/articles/79aaeb8db5731chttps://docs.astral.sh/ruff/integrations/型をつけよう
Pythonには静的型付けがなく、ある変数になんの型が入っているのかは実行時にならないとわかりません。コードによっては、「ある場所では整数型が入っている変数だったのに、いつの間にか文字列が入っている」「数字と文字列とがごっちゃになったリストが存在する」等といった地獄のような状況が起こり得ます。 このようなPythonの特徴は、小さいコードを書くときには型を気にせず高速にコードが書ける、というメリットが上回りますが、大規模なコードになればなるほどコードが追いにくくなります。 そこで、Pythonに型をつけ、またデータをひとまとまりにして扱うためのテクニックについてご紹介します。
変数に型をつける
手始めに、通常の型アノテーションを紹介します。Pythonでは次のような形で型情報を付加することができます。数値型や文字列型以外にも、typing モジュールを使うことでList やAny と言った型を表すことができます。また、任意のクラスも型としてアノテーションに用いることができます。
# 変数に型アノテーションをする
x: int = 1
y: str = "hoge"
# typingモジュールを用いる
people: List[str] = ['Alice', 'Bob', 'Charlie']
raw_data: Any = some_func()
# クラスも型として使える。
class Dog:
def __init__(self):
...
fake_dog: Dog = Dog()
real_dog: Dog = Dog()
# もちろん組み込みのクラスも。
import datetime
now: datetime.datetime = datetime.datetime.now()
また、このような型アノテーションは関数の引数、返り値にもつけることができます。
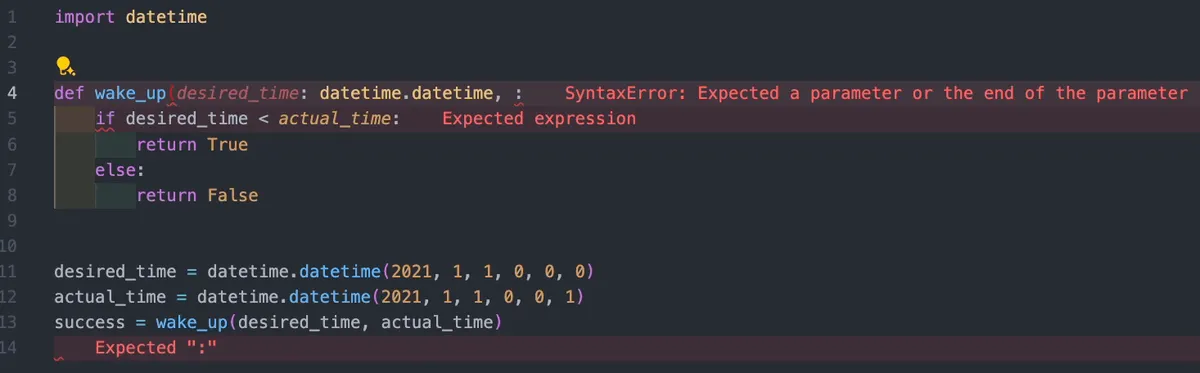
def wake_up(
desired_time: datetime.datetime,
actual_time: datetime.datetime
) -> bool:
if desired_time < actual_time:
return True
else:
return Falseこのような単純な型であれば、自分で付けなくともVSCodeのLanguage Serverが自動で推論して出してくれることもあります。この機能はinlay機能と呼ばれていて、VSCodeのsetting.jsonに以下のように書き加えることで勝手に型を出してくれます。(公式ドキュメント)
{
"python.analysis.inlayHints.functionReturnTypes": true,
"python.analysis.inlayHints.variableTypes": true,
}↓こんな感じです。出してくれた型をダブルクリックすると挿入できて便利です。
ひとかたまりのデータを表す
大規模なコードを書く場合には、往々にしてデータを構造化することが求められます。 例えば、レストランを例にして考えてみましょう。
単純にレストランでの注文データを構造化してみます。dictで表すならこんな感じでしょうか。
order = {
"table": 1,
"dishes": ["天津飯", "麻婆豆腐定食", "唐揚げ定食", "日替わりセット"]
}これでも使えないことはない…ですが、料理名がハードコーディングされていたり、情報の追加(「天津飯のグリーンピース抜きオプションを追加したい」という要望が出たらどうしますか?)がしにくかったり、保守性が❌️なコードになっています。 では、この注文をもっと拡張性が高くなるように変更してみます。 まずは、Order クラスをdataclassとして定義してみます。こうすることで、クラスがひとまとまりのデータであることが明示できますし、frozen=True を使うことによってデータの更新を防ぐことができます(Listなどミュータブルな型を使うと変更できてしまうので、使わないようにしましょう)
from dataclasses import dataclass
@dataclass(frozen=True)
class Order:
table: int
dishes: tuple[Dish]また、Dishクラスも定義してみます。今回はidを振って識別子とし、料理名を変更できるようにします。
@dataclass(frozen=True)
class Dish:
id: int
name: str このように定義することで、容易にひとまとまりのデータを扱うことができます。例えば、Dish に税抜き価格の情報を付加しようと思えば次のように簡単に追加できます。
@dataclass(frozen=True)
class Dish:
id: int
name: str
price: intdataclass はPythonに標準でついている機能ですが、pydantic というライブラリを使うことで、バリデーションをしたり、jsonにシリアライズしたりといったことが簡単にできるようになります。めっちゃおすすめです。(FastAPIを使うと自然に使っているので知ってる人も多いと思いますが…)
…以上のように、知っている人から見ればそれはそうな情報ばかりを書き連ねてしまったので、もう少し便利な情報も書いておきます。 まずは、Python標準のdataclassですが、実はimportを書き換えるだけでpydantic のdataclass に置き換えることができます。pydantic のほうが機能が豊富なので、複雑なアプリを作るときはこちらを使うほうが良いでしょう。 →Pydanticの公式ドキュメント
また、pandasで作ったデータフレームをバリデーションするpandera というライブラリもあります。(公式ドキュメント)こんな感じで、データフレームにバリデーションを追加できます。データフレームを加工してコネコネするときにとても便利だと思います。
import pandas as pd
import pandera as pa
# data to validate
df = pd.DataFrame({
"column1": [1, 4, 0, 10, 9],
"column2": [-1.3, -1.4, -2.9, -10.1, -20.4],
"column3": ["value_1", "value_2", "value_3", "value_2", "value_1"],
})
# define schema
schema = pa.DataFrameSchema({
"column1": pa.Column(int, checks=pa.Check.le(10)),
"column2": pa.Column(float, checks=pa.Check.lt(-1.2)),
"column3": pa.Column(str, checks=[
pa.Check.str_startswith("value_"),
# define custom checks as functions that take a series as input and
# outputs a boolean or boolean Series
pa.Check(lambda s: s.str.split("_", expand=True).shape[1] == 2)
]),
})
validated_df = schema(df)
print(validated_df)個人的には、データをクラスで表してバリデーションするこちらの書き方が好みです:(class-based API)
import pandas as pd
import pandera as pa
from pandera.typing import Index, DataFrame, Series
class InputSchema(pa.DataFrameModel):
year: Series[int] = pa.Field(gt=2000, coerce=True)
month: Series[int] = pa.Field(ge=1, le=12, coerce=True)
day: Series[int] = pa.Field(ge=0, le=365, coerce=True)
class OutputSchema(InputSchema):
revenue: Series[float]
@pa.check_types
def transform(df: DataFrame[InputSchema]) -> DataFrame[OutputSchema]:
return df.assign(revenue=100.0)
df = pd.DataFrame({
"year": ["2001", "2002", "2003"],
"month": ["3", "6", "12"],
"day": ["200", "156", "365"],
})
transform(df)
invalid_df = pd.DataFrame({
"year": ["2001", "2002", "1999"],
"month": ["3", "6", "12"],
"day": ["200", "156", "365"],
})
try:
transform(invalid_df)
except pa.errors.SchemaError as exc:
print(exc)終わりに
(非常に無計画な文章をつらつらと書いてしまった自覚があります…読みにくくてすみません…!)
以上、Pythonの大規模コードを読みやすくするtipsでした!


