
💡
今日は2024年12月25日です。そしてあと1週間で2025年になります!
はじめに
jackアドベントカレンダー2024もついに最終日を迎えました。
最終日担当のめろです。
2024年8月1日 ~ 9月5日に開催されたMUFG Data Science Basic Camp 2024で1位を取ることができたので、その話をしようと思います。
突然ですが皆さん、去年の最終日の記事が何だったか覚えていますか?
正解は前代表のすけさんによる「代表になります!」って記事です。これを見た時、「やばい」って思いました。そうです。自分には最終日っぽい記事を書くことが出来なかったのです。
「あと1週間で2025年になります!」って記事にして対抗しようと思いました。
ただ、1行で終わってしまいました。
という訳で最終日らしくない記事になってしまいましたがお付き合いください。
1. コンペの概要
2024年の夏にMUFG主催で、上級者向けのChampion Shipと初中級者向けの Basic Campという2つの機械学習コンペが開催されました。
自分が参加したのはBasic Campで、SIGNATECloudという学習用サイトで開催されました。ただSIGNATECloudはコンペ期間のみ利用可能だったので現在は見ることができません。
| MUFG Data Science Basic Camp 2024 | |
| 課題 | 個人向けローンの返済可否予測 |
| レベル目安 | 初中級者 |
| データ | テーブルデータ、不均衡データ |
| 評価指標 | AUC |
| 特徴 | やや不均衡ではあるが、よくあるテーブルデータでデータ分析の基礎を試せる |
2. 参加前の自分のレベル
参加時点での情報系の実績や資格は以下の通りです。
- GCI 2023 Winter 修了
- AtCoder(Algorithm 水色, Heuristic 青色)
- G検定
- 基本情報技術者
- 応用情報技術者
情報学に対する知識やコードを書くスキルはありましたが、機械学習コンペに参加して、時間をかけてモデルを作成したり、改善したりをした経験はありませんでした。
そのため今回のコンペでは、内容が近かったkaggleのHome Credit Default Riskの解法を見ながらたくさんの試行錯誤を繰り返しました。
3. 解法の全体像
実はSignateのページに表彰式で発表したときのスライドを載せていただいているのでよかったら見てください。
MUFG Data Science Champion Ship 2024 | SIGNATE - Data Science Competition
解法の方針
今回は初中級者向けであったため以下の特徴を持ったデータでした。
- 外れ値、欠損値、表記揺れがほぼない(purposeという特徴量は除く)
- 特徴量同士の組み合わせで、意味がある特徴量を生成できない
このような特徴を持ったデータであったため、凝った前処理や、自分で考えた特徴量生成はすべて精度悪化につながりました。そのため「機械に判断を任せること」を今回の方針としていました。
解法の全体像
purposeという特徴量が唯一欠損値が多かったため、補完なし、”purpose_non”という文字列で埋める、LightGBMで予測して埋めるの3種類による欠損値補完をしました。
その後は同じ処理を行い(乱数シードは変えています)6つのLightGBMのモデルを作成し、アンサンブル(組み合わせて精度を高めること)をして最終提出ファイルとしました。
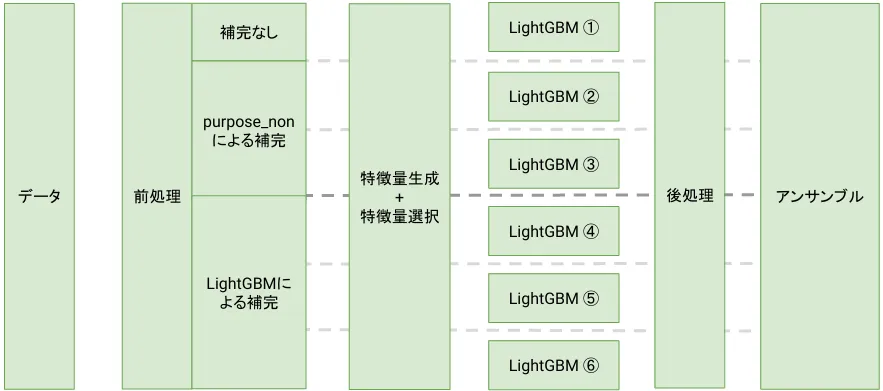
4. 解法紹介
特に工夫した特徴量生成+特徴量選択の部分に絞って説明します。
ここでは、特徴量生成で精度向上につながりそうな特徴量を総当たり的にすべて生成したあとに、特徴量選択でほんとうに意味がある特徴量だけを残すことをしています。自分で新しい特徴量を考えても上手くいかなかったため、機械に考えてもらおうという作戦です。
特徴量生成
精度向上につながりそうな新しい特徴量の作り方として以下のものがあります。
- 特徴量同士の四則演算
- 特徴量の統計値(最大値、最小値、中央値、平均値、最頻値など)
- 遺伝的アルゴリズムによる特徴量生成
- 近傍500個での目的変数の平均
- 欠損値であるかのフラグ
これらは kaggleのHome Credit Default Riskの上位解法を参考にしました。
全て試しましたが、下3つは精度向上に寄与しませんでした。そのため今回は、特徴量同士の四則演算と特徴量の統計値による特徴量生成を行いました。
特徴量選択
特徴量生成を総当たり的に行ったため、大量の特徴量が生成されました。
ただこのままでは、精度悪化につながってしまう特徴量があったり、モデルの学習時間が長くなったりといいことがありません。そこで本当に意味がある特徴量だけを残す必要があります。
これが「特徴量選択」です。この特徴量選択の方法としては大きく分けると以下のものがあります。
- 統計的手法で個々の特徴量を評価
- 機械学習モデルで最適な特徴量組み合わせを探索
- 機械学習モデルで簡易的に特徴量を評価
今回は上2つの方法を使って2段階による特徴量選択を行いました。それでは説明します。
1段階目:trainとtestで分布が異なるか
すべての特徴量に対して、trainとtestの分布を比較します。もし分布が大きく異なっている場合は、意味のない特徴量である可能性がかなり高いです。そのためコルモゴロフ・スミルノフ検定によって分布が異なるかを評価して、分布が異なる場合は削除しました。
2段階目:1つずつ特徴量を追加して、モデルの精度が上がったら採用するを繰り返す
ほんとうは特徴量のすべての組み合わせを試して最も精度がよくなる組み合わせを探したいです。ただこの段階で残っている特徴量が500ほどあったので、すべての組み合わせを試そうと思うと、計算量が2の500乗になり爆発してしまいます。
そのためどこかで妥協する必要があります。
今回は1つずつ特徴量を追加して、モデルの精度が上がったら採用するを繰り返しました。そして、すべてを見終わったときの特徴量の組を最も精度向上に寄与する特徴量の組だとしました。
ただもちろん誤魔化している部分があります。何か分かりますか?
最も大きな欠点は「順番が最初に近いほど採用されやすい」ことです。
順番が最初に近いほど採用されやすい
- 原因
簡単な例として「年収」と「年収の中央値」いう特徴量があったとします。そして、「年収」は「年収の中央値」よりも目的変数と関係があり、「年収」という特徴量が既に採用されている場合は「年収の中央値」という特徴量を加えても精度は上がらないとします。ただ、モデルに追加する順番が「年収の中央値」の方が前だった場合、これまでに採用された特徴量に年収に関係するものがないと「年収の中央値」という特徴量によりモデルの精度が上がる可能性が高く、採用されてしまいます。
このようにして順番が異なると、ある特徴量の下位互換であったとしても採用される確率が上がってしまいます。
- 自分がした対策
ではこの順番による影響をどうやったら抑えられるでしょうか。
自分が行った対策は2つあります。
1つ目の対策は特徴量の順番をシャッフルすることです。そして異なる特徴量の順番によって作成した6つのモデルをアンサンブル(組み合わせて精度を高めること)をすることにより、順番の影響をできるだけ抑えました。
ただ、これだと精度悪化につながる特徴量が最初の方に偏ってしまったらどうするの?と思うかもしれません。そのため2つ目の対策をしました。
2つ目の対策は重要な特徴量をあらかじめ採用された特徴量とすることです。もともとある特徴量の中でも特に目的変数との関係が高いものについては、あらかじめ採用された特徴量としました。これによって、精度悪化につながる特徴量が最初の方にあっても採用されないようにしました。
5. まとめ
初中級者向けとはいえども優勝することができて、とても嬉しかったです。
ただ今回はSignate Cloud上で開催されていたためメダル付与がありませんでした。
そのため、今後はメダルを目指して頑張りたいです!
最後に
本日25日の記事でjackアドベントカレンダーは終了です!ありがとうございました!
もし未読の記事がありましたら是非是非読んでみてください!

